Facturation électronique : le calendrier du 1er…

Face à des assurés toujours plus imaginatifs pour créer des scenarii de fraude et à l’apparition de la fraude organisée, les assureurs doivent s’équiper afin de lutter contre ce fléau.

Les assureurs n’échappent pas à la recrudescence des cas de fraude observés dans l’ensemble des secteurs de l’économie (fraude à l’assurance-maladie, aux impôts, aux voyages SNCF,…). En 2013 selon l’ALFA (l’Agence pour la Lutte contre la Fraude en Assurance), l’assurance française (en dommages) a détecté
44 814 actes de fraudes, pour un montant recouvré de 214 millions d’euros. La fraude désigne les actes ou les omissions délibérées dans l’intention de tromper l’assureur pour en tirer un avantage financier. Les façons de frauder sont les suivantes :
tricher à la souscription pour payer moins cher ;
tricher lors d’un sinistre pour obtenir plus d’indemnités ;
simuler un sinistre pour s’enrichir.
Face à des assurés toujours plus imaginatifs pour créer des scenarii de fraude et à l’apparition de la fraude organisée, les assureurs doivent s’équiper afin de lutter contre ce fléau. En 2014, les assureurs français auraient consacré 20 millions d’euros au déploiement de moyens de lutte anti-fraude alors que 81% des assureurs ont recours aux techniques de détection automatisée.
Ce dossier vise à expliciter les enjeux à lutter contre la fraude et les moyens techniques mis en œuvre par les assureurs. En effet, en cas de fraude, le code des assurances prévoit des sanctions auprès de l’assuré qui impactent directement le ratio sinistres / primes de l’assureur. Il appartient alors aux assureurs de mettre à disposition de leur équipe fraude la solution la plus pertinente au regard de leur contraintes (coût opérationnel de la solution, performance souhaitée, historique fraudes et data disponibles,…).
La fraude peut être détectée dès la souscription du contrat par notamment des contrôles auprès de l’AGIRA. Les bases de l’AGIRA mettent à disposition des assureurs l’historique des contrats résiliés soit par l’assuré, soit par l’assureur. Par exemple, un assuré qui souscrit un contrat d’auto alors qu’il a été résilié d’un assureur concurrent peut voir ses garanties déchues et son contrat frappé de nullité.
C’est bien lors que la déclaration de sinistre que la fraude est majoritairement détectée : des solutions permettent en effet de donner automatiquement un score fraude à chaque sinistre déclaré, avant une investigation manuelle par les gestionnaires de l’équipe fraude. Si besoin, l’équipe fraude peut faire appel à
8 Manœuvre frauduleuse visant à tromper l’assureur
des experts ou même à des détectives privés. Si la fraude est prouvée, des sanctions spécifiques sont prévues selon la gravité des préjudices :
sous l’emprise de stupéfiants ;

Avec 27 000 fraudes détectés et 110 M€ recouvrés, l’assurance automobile concentre la majorité des actes frauduleux identifiés sur les activités IARD. Cette fraude représenterait au global plus de 1 milliard d’euros par an, soit 5 points de marge brute de l’assurance AUTO.
La fraude constitue un enjeu d’autant plus significatif que le marché AUTO est soumis à de fortes pressions en termes de rentabilité et de concurrence. En effet, le combined ratio de cette activité se maintient au-dessus de 100 % depuis 2005. De plus, l’introduction de la résiliation infra-annuelle par la loi HAMON, ainsi que l’importance croissante des comparateurs internet dans le parcours client, ont rendu ce marché très concurrentiel. Chaque point de rentabilité gagné ou perdu présente dès lors un enjeu hautement stratégique.
Ces chiffres correspondent à des estimations au niveau du marché français. Les études statistiques sur la fraude mettent en évidence que certains profils clients présentent un risque sensiblement supérieur à la moyenne. L’impact de la fraude pourrait ainsi dépasser significativement 5 points de marge sur ces segments à risque.

L’assurance AUTO présente une grande variété de fraudes qui s’explique notamment par :
La fraude à l’assurance AUTO relève principalement de particuliers recherchant un gain ponctuel dans une approche purement opportuniste. Cette fraude peut néanmoins être le fait de bandes organisées qui vont exploiter des failles juridiques ou contractuelles, voire des lacunes dans les procédures de contrôles des assureurs.
Ce cas de figure s’est présenté aux assureurs canadiens qui ont été victimes d’une fraude sophistiquée pour un montant estimé de 1 milliard de dollars. Les réseaux de fraude achetaient une voiture de luxe, recrutaient de faux passagers puis provoquaient une collision légère avec un automobiliste lambda. L’assureur de ce dernier se voyait ensuite demander des indemnisations au titre de prétendus dommages matériels et surtout corporels. Les fraudeurs déclaraient en effet des blessures et traumatismes multiples sur la base de faux certificats médicaux et de fausses factures de soins. Cette fraude n’a été possible que par une faiblesse du système d’assurance canadien qui indemnise les dommages au tiers sans chercher à établir les responsabilités. Les assureurs ont également été incriminés pour leur laxisme face au risque de fraude. Ces derniers considéraient en effet qu’il était moins couteux de payer des dédommagements indus que d’engager des investigations. Cet exemple illustre l’importance des mécanismes visant à minimiser l’aléa moral via la législation, les clauses contractuelles et les procédures de contrôle.
LA DÉTECTION AUTOMATIQUE DE LA FRAUDE : UNE NÉCESSITÉ OPÉRATIONNELLE
L’année 2014 s’est traduite par plus de 8 millions de sinistres AUTO indemnisés parmi lesquels environ 27 000 cas frauduleux identifiés, soit une fréquence de 0,3 %. Ce taux apparait néanmoins fortement sous-estimé puisqu’il ne concerne que les fraudes détectées par les assureurs. La proportion réelle de fraudes peut être estimée à quelques pourcents en assurance AUTO.
Outre cette faible fréquence, les cas frauduleux présentent souvent des caractéristiques relativement similaires aux cas non-frauduleux. Il n’existe pas de variable ou de règle particulière permettant de caractériser les cas de fraude de manière simple et robuste.
D’un point de vue schématique, détecter la fraude consiste à chercher une épingle jaune dans une botte de paille. D’un point de vue technique, cela revient à traquer les signaux faibles caractérisant la fraude.
Dans cette lutte, les gestionnaires de sinistres se retrouvent en première ligne. Ces derniers peuvent en effet signaler les cas suspicieux afin d’engager des investigations. Cette identification est réalisée sur la base de l’expérience acquise dans l’analyse des éléments du sinistre, mais également sur le ressenti de l’échange avec l’assuré. Cet aspect humain constitue une spécificité des gestionnaires qui ne peut être reproduit dans les modèles de détection de fraude.
Néanmoins, un assureur couvrant 100 000 contrats doit traiter en moyenne 20 000 dossiers par an avec une équipe d’une dizaine de gestionnaires. Ces derniers ne peuvent réaliser une analyse approfondie de chaque sinistre sans risquer de compromettre la fluidité de l’ensemble de la gestion. Par ailleurs, la fraude constitue un phénomène trop complexe pour être complètement appréhendé par un gestionnaire, aussi expérimenté et psychologue soit-il.
Le recours à des modèles automatiques de détection constitue dès lors une nécessité opérationnelle pour lutter de manière efficace contre la fraude. Ces modèles s’articulent autour de 3 approches distinctes :

Cette approche consiste à définir un corpus de règles binaires caractérisant chacune une situation suspecte. Un sinistre vérifiant une de ces règles est considéré comme potentiellement frauduleux et devra en conséquence faire l’objet d’une vérification voire d’une investigation approfondie.
Les règles retenues correspondent généralement à une formalisation d’un certain « bon sens » et de l’expérience des gestionnaires en matière de fraude. Certaines règles quantitatives peuvent être calibrées sur la base d’analyses statistiques (ex : seuil fréquence ou coût atypiques). Néanmoins, cet aspect quantitatif reste limité à une simple analyse statistique univariée.
Les types de fraude étant intrinsèquement liés à la garantie considérée, les règles de décision sont généralement définies au niveau de chaque garantie. Les modèles de place retiennent entre 10 à 20 règles par garantie ce qui aboutit in fine à un corpus d’une centaine de règles.
L’avantage principal de ce type de modèle réside dans sa simplicité opérationnelle. En effet, la mise en œuvre d’une telle approche ne requiert ni base de données spécifique, ni travaux de modélisation complexe. La notion de règle binaire présente par ailleurs un caractère intelligible pour l’ensemble des acteurs impliqués qui peuvent ainsi participer à la construction du modèle, le mettre en œuvre et le faire évoluer.
Des règles de décision binaires apparaissent néanmoins trop rudimentaires pour capter la complexité du phénomène de fraude. Cette insuffisance peut conduire à un modèle avec une très faible spécificité qui produira de nombreux faux positifs. Une proportion élevée de cas identifiés comme suspects, bien qu’en réalité non frauduleux, peut rendre les résultats peu exploitables avec un périmètre de sinistres à investiguer trop étendu. Les coûts d’investigation risquent alors de se révéler globalement supérieurs au montant de fraude à recouvrer. Une sélection de règles suffisamment restrictives permet cependant de minorer ce risque.
Cette approche présente sans doute le meilleur compromis entre performance et coût opérationnel. Son caractère sommaire limite forcément ses performances de détection face aux cas complexes de fraude. Néanmoins, ce type de modèle permet de définir un premier périmètre d’investigation ciblé sur les cas les plus à risque. In fine, bien qu’elle ne se suffise pas à elle-même, cette approche par règles de décision constitue une première étape indispensable pour tout assureur souhaitant mettre en place un système de détection automatique de la fraude. Ce type de modèle est d’ailleurs implémenté chez une majorité des acteurs du marché.

Cette approche vise à construire un modèle d’apprentissage statistique permettant de prédire l’appartenance des sinistres déclarés à une des 2 classes suivantes :

Ce modèle de classification permet d’estimer la probabilité d’appartenance à la classe « sinistre frauduleux », notée Yˆ, du i sinistre i par rapport à un ensemble de variables explicatives X j :

Le modèle est calibré à partir d’une base fraude qui contient pour chaque sinistre du périmètre historique retenu :
La complexité du phénomène de fraude impose de considérer de nombreuses variables explicatives issues de différentes sources (base sinistre, base assuré, base commerciale,…). La création de cette base constitue la principale contrainte opérationnelle de l’approche. En effet, l’identification de la classe d’appartenance des sinistres requiert de disposer d’un historique des fraudes détectées. L’approche supervisée ne peut donc être envisagée qu’à partir d’un dispositif de lutte contre la fraude préexistant.
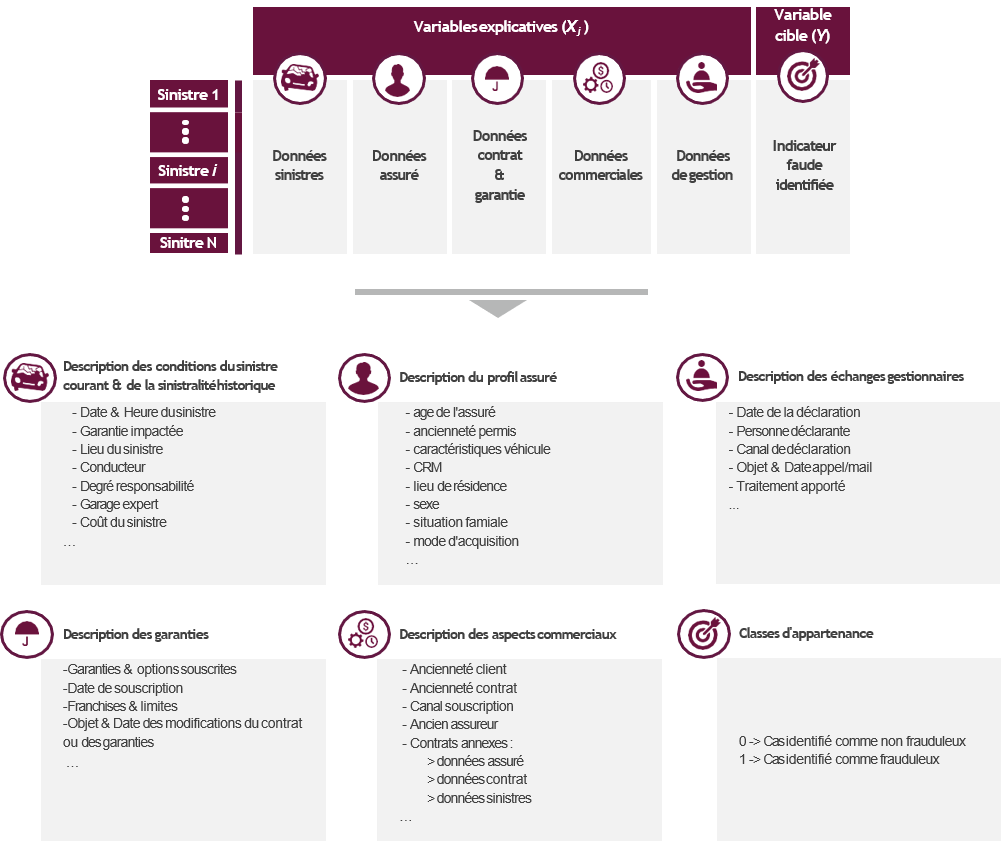
L’approche supervisée vise à résoudre une problématique de classification. La démarche à mettre en œuvre reprend donc celle appliquée par les services de tarification dans le cadre des modèles de transformation, de rétention ou de propension :

La modélisation de la fraude présente néanmoins 2 spécificités
majeures qui impactent sensiblement la démarche opérationnelle :
L’approche supervisée permet in fine de construire un modèle de détection automatique des fraudes prenant en compte la complexité du phénomène d’une part, et reposant sur des bases objectives d’autre part. Le recours à des algorithmes de type machine learning permet en effet de capter la complexité des données selon une approche « data driven ». Le caractère
« boite noire » de ces modèles constitue souvent une cause de disqualification dès lors qu’une certaine traçabilité est requise. Cependant, dans un contexte de détection de fraude, le besoin de traçabilité apparait moins prégnant ce qui permet d’envisager ce type d’algorithme.
Le talon d’Achille de l’approche se situe au niveau de la base fraude. En effet, le modèle apprend à identifier les fraudes détectées qui lui sont soumises via la base d’apprentissage. Un type de fraude qui n’a jamais été détecté par l’entité ne pourra pas être identifié par le modèle puisqu’il ne l’aura jamais appris. La capacité prédictive du modèle est donc conditionnée par la qualité du dispositif d’identification des fraudes préexistant sur lequel repose la base d’apprentissage. A titre de rappel, la fraude à l’assurance AUTO représenterait plus de 1 milliard d’euros pour seulement 110 M€ recouvrés. Cet écart illustre les limites de l’approche supervisée qui constitue néanmoins un maillon essentiel du dispositif de lutte contre la fraude.
Cette approche vise à développer un modèle d’apprentissage statistique permettant de regrouper les données en différentes classes homogènes non connues a priori. Le modèle va analyser la structure des données et classer les observations selon leur degré de similitude. L’objectif ne consiste plus à déterminer des règles permettant de prédire l’appartenance à une classe cible, mais à identifier des règles de regroupement au sein de différentes classes définies par le modèle lui-même. D’un point de vue schématique, l’approche non supervisée revient à laisser le modèle analyser les données sans lui préciser ce qu’il doit trouver.
Cette approche permet notamment d’identifier les observations présentant une structure atypique au sein d’une base de données. En formulant l’hypothèse qu’un sinistre affichant des caractéristiques atypiques dissimule potentiellement une fraude, cette approche peut être appliquée dans un contexte de détection automatique des cas frauduleux.
Le modèle réalise son apprentissage sur une base de données similaire à celle de l’approche supervisée mais limitée aux seules variables explicatives. L’absence de variable cible présente 2 avantages majeurs :
Les modèles non supervisés reposent tous sur le même principe
: une mesure de la singularité de chaque observation. Cette mesure peut correspondre à une distance ou une densité, estimée de manière locale ou globale, selon le modèle considéré. Les algorithmes non-supervisés se répartissent en 3 grandes familles :
L’absence de variable cible implique qu’il n’existe pas de phase de paramétrage, de sélection de variable ou de validation du modèle. Cette spécificité présente l’avantage de la simplicité opérationnelle. Néanmoins, l’absence de feedback sur la qualité des résultats peut parfois se révéler déroutante. L’utilisateur en est réduit à accorder une confiance aveugle à son modèle.
Cet inconvénient peut être atténué selon 2 méthodes :
L’approche non supervisée apparait encore peu considérée par les assureurs dans le cadre de la détection de fraude. Cette dernière présente pourtant des avantages certains, à commencer par son absence de prérequis permettant une mise en œuvre immédiate, ainsi que sa capacité à identifier des types de fraudes encore jamais détectées. Néanmoins, l’hypothèse sous-jacente à l’approche, qui lie les caractères frauduleux et atypique, peut s’avérer inexacte. L’impossibilité de paramétrer et de valider le modèle ne permet pas de confirmer cette hypothèse pourtant fondamentale. Le risque consiste dès lors à engager des investigations couteuses sur les cas considérés comme atypiques par le modèle bien qu’en réalité non frauduleux. Cette faille pousse à considérer l’approche non supervisée comme un simple complément de l’approche supervisée

DETECT FRAUD BY ANALYZING SOCIAL NETWORKS
En 2014, deux tiers des assureurs avaient amélioré leur dispositif de détection de fraude, avec une hausse moyenne de 3 % du nombre de cas identifiés. Cette performance modeste illustre la complexité de détecter les cas frauduleux. L’assureur ne dispose en effet que de données limitées qui ne concernent ni le comportement, ni le mode de vie de ses assurés. Ces informations, particulièrement pertinentes pour identifier la fraude, n’ont pourtant jamais été aussi disponibles, collectées et exploitables via les réseaux sociaux.
L’analyse des réseaux sociaux10 pour combattre la fraude est abondamment citée comme cas d’usage dans la littérature relative au Big Data. L’exploitation actuelle de ces réseaux se limite cependant à une analyse manuelle et a posteriori des profils suspects. La transition vers une exploitation industrielle constitue un enjeu majeur des futurs dispositifs de lutte contre la fraude.
Si les GAFA (Google, Amazon, Facebook, Apple) connaissent suffisamment leurs utilisateurs pour en prédire le comportement, qu’en est-il des assureurs ? Quelles données apparaissent pertinentes pour détecter la fraude ? Quelles informations sont réellement disponibles sur les réseaux sociaux ?
Dès lors que l’on s’intéresse aux données personnelles, Facebook s’impose comme une source d’informations incontournable. Les données publiques de ses utilisateurs sont d’ailleurs déjà utilisées par les assureurs d’autres pays pour prouver certains cas de fraude :
volée » ;
Au-delà de l’analyse de contenu publié par un assuré, les données concernant le réseau d’amis peuvent s’avérer précieuses dans la fraude en RC AUTO. En effet, l’analyse des liens entre les individus impliqués dans un accident permet de savoir si ces derniers se connaissent. Un degré de proximité élevé implique un fort risque de fraude à la déclaration, les assurés s’étant potentiellement mis d’accord pour modifier le contexte ou les conséquences de l’accident.
L’accès aux données et aux services de Facebook se fait au travers d’une API11. Un développeur peut utiliser l’API de Facebook pour requêter des données publiques (évènements, participants, pages de fans, etc..) ou des données personnelles. La collecte de données personnelles nécessite cependant une connexion avec l’utilisateur, ce qui suppose la création d’une application, d’un site web ou d’un système d’inscription lié à Facebook.
Le numéro deux de l’assurance auto aux Etats-Unis (GEICO) impose ainsi l’inscription à son site via Facebook, ce qui lui permet de collecter des données sur l’ensemble de ses clients. Cette approche suppose néanmoins une totale dépendance vis à vis de Facebook qui est le seul à décider des modalités d’usages et des données disponibles via son API. Des dizaines de startups en ont fait l’amère expérience l’année dernière lorsque Facebook a décidé de ne plus rendre disponible la liste d’amis des comptes publics. Les nouvelles règles de l’API ne permettent plus de récupérer l’ensemble des amis d’un assuré, mais seulement ceux utilisant également l’application.
Cet exemple illustre le risque de dépendance induit par l’utilisation de l’API mise à disposition par Facebook qui peut à tout moment et de manière unilatérale « couper le robinet ». Ce risque n’est d’ailleurs pas spécifique à Facebook mais concerne toute API dont les règles sont définies exclusivement par l’entreprise source. Les assureurs doivent ainsi être conscients de ce risque avant d’engager des développements impliquant le recours à une API.

Les données Facebook sur les utilisateurs présentent une réelle pertinence dans le cadre de la lutte contre la fraude. L’analyse automatique du contenu publié par un client (en arrêt maladie mais postant des photos de vacances à la plage) reste à ce jour au stade expérimental et requiert l’utilisation d’outils d’analyse spécifiques (text mining / analyse d’image). Mais d’autres données comme le réseau d’amis peuvent d’ores et déjà faire l’objet d’une exploitation industrielle.
L’accès à ces données présente un réel coût d’entrée sans garantie sur la pérennité des solutions développées. En dernier recours, une collecte des informations par web scraping permettrait de s’affranchir des contraintes de l’API au prix d’une technicité accrue.
Le principal obstacle à l’exploitation des réseaux sociaux pourrait in fine ne pas être technique mais juridique. Une collecte massive d’informations personnelles viendrait en effet contredire quelques principes clés de la CNIL12 :
de pouvoir accéder, contester ou rectifier les données collectées.
Malgré un potentiel certain, l’exploitation des réseaux sociaux au sein des modèles de détection de fraude ne pourra être envisagée tant que cette hypothèque juridique n’aura pas été levée.
Si vous souhaitez en savoir plus sur nos solutions d'IA, rendez-vous sur notre site web Heka : https://heka.sia-partners.com/
Contact : david.martineau@sia-partners.com

